0x00 前言
某风控SDK采集设备指纹信息,二次加密后使用HTTPS协议传输到服务端进行风控判定,如果想要绕过风控,就需要把二次加密的算法逆出来,篡改数据报文中的设备信息,从而绕过检测。
0x01 定位打点
1. 定位Java层关键函数
通常定位关键代码是使用搜索大法,方法虽简单有效,但是局限性也比较大,比如遇到字符串混淆加密或出现大量的匹配结果,都会使分析受到较大的阻力。为了能精确定位到关键代码,这次我们换一种思路定位分析入口,因为指纹信息是使用HTTPS协议进行传输的,可以使用@r0ysue大佬写的r0capture抓包工具进行分析,该工具会Hook底层的网络接口,并打印调用栈信息,然后可以通过堆栈信息直接定位到应用Java层的发包函数作为分析入口。如下所示,定位到O000O00000OoO.a方法为分析点
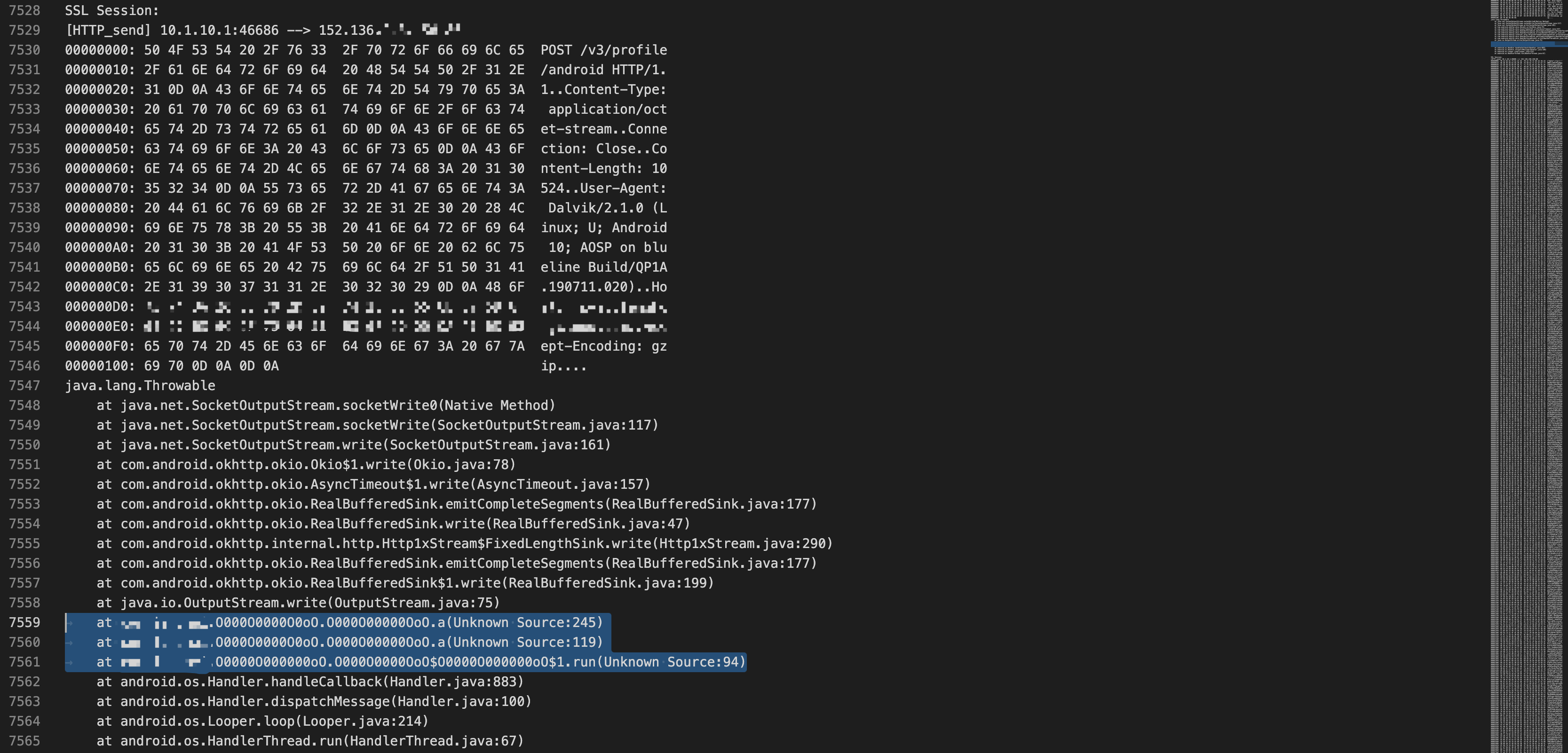
进一步分析函数调用,最终定位到了以下代码位置
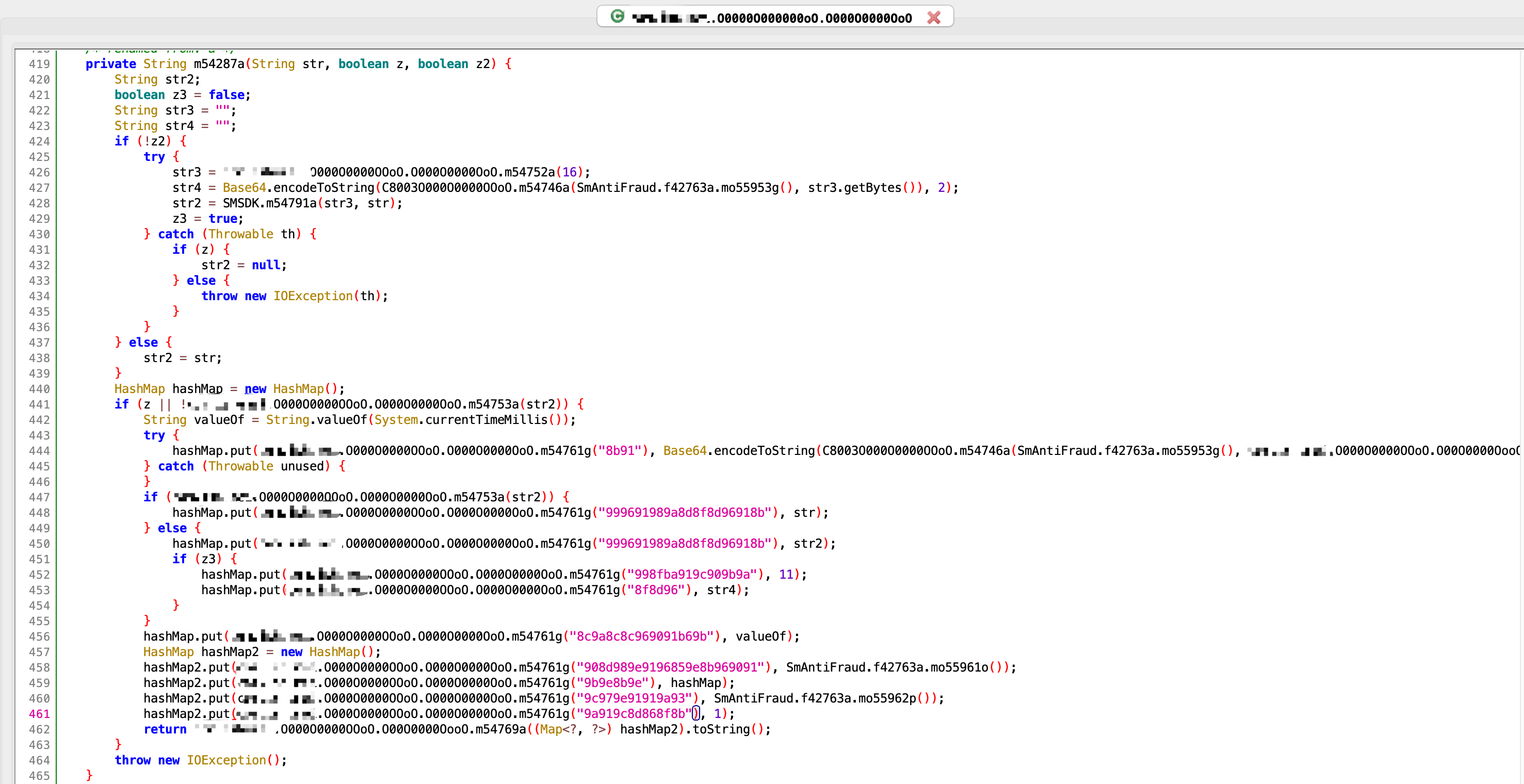
hashMap.put的key值其实就是请求报文中的参数key,只是截图中的key被加密了。这里得提一下jeb这个工具,收费的工具还是要牛逼一点,它可以自动把加密字符串给解密出来,如下所示
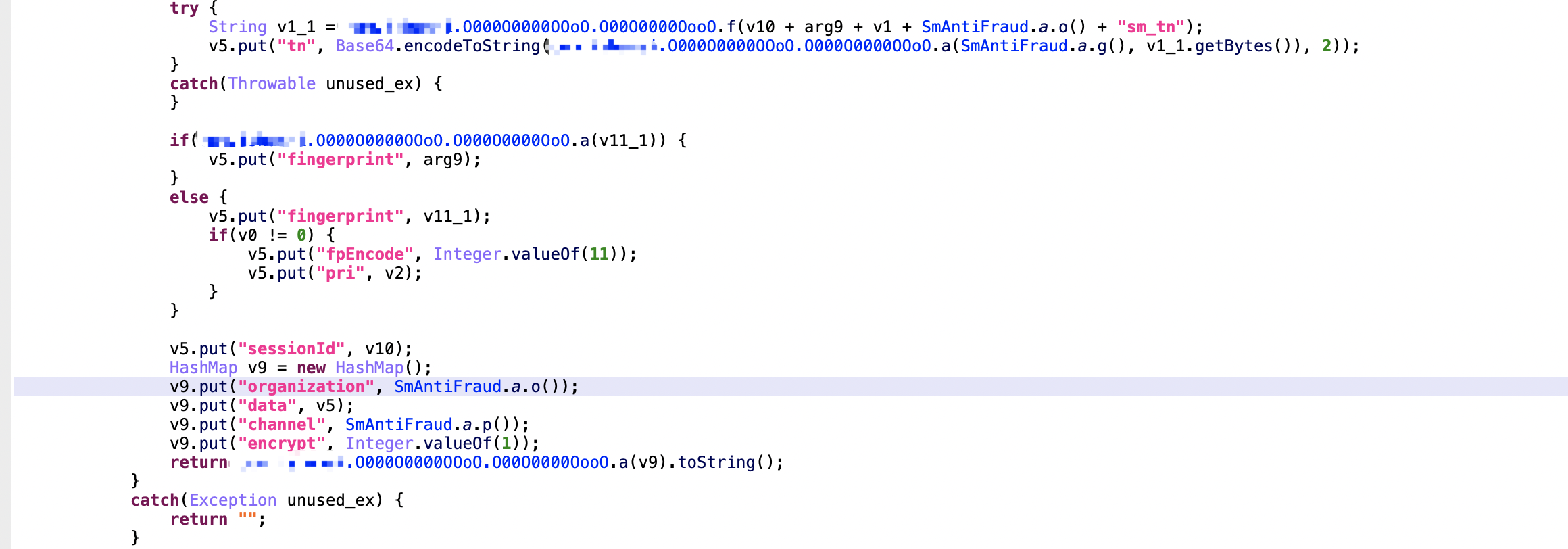
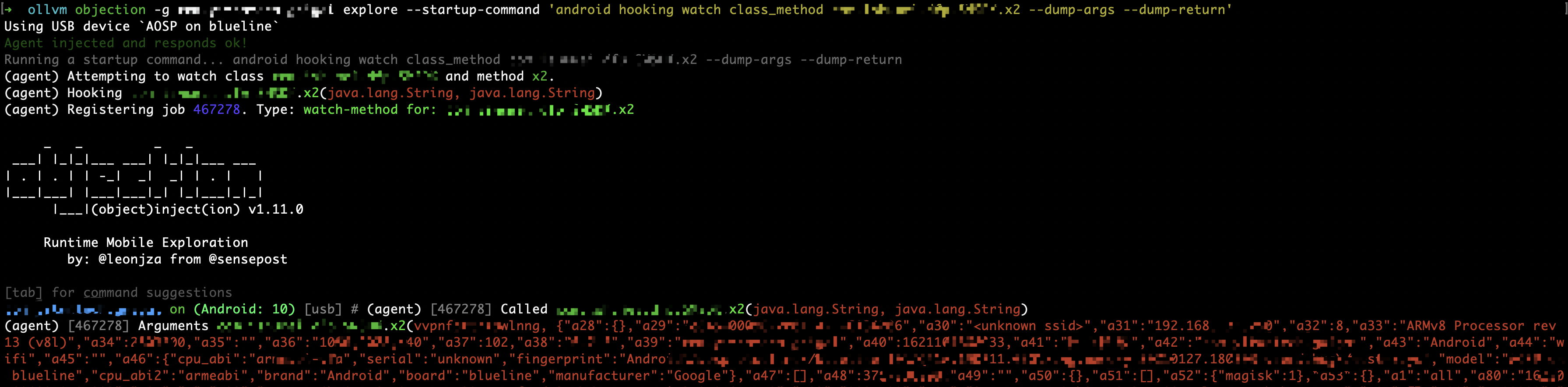
当然并不是说这里使用jeb就可以直接搜索关键字定位到代码,字符串在smail窗口依然是加密状态,只是在Java反编译窗口,jeb自动解密了字符串。进一步分析,最终定位到了x2这个native方法

objection hook确认一下,启动objection的时候注意使用--startup-command参数,避免错过hook时机,可以看见arg2参数是一堆指纹信息,并且返回值与burp抓包的数据一致
2. 定位so文件
通常实现native方法的so文件都是在native方法所在类的静态代码块中进行加载的,当然本案例也不列外。但有些应用为了隐藏实现native方法的so文件,会在其他初始化类中进行so加载,增加了攻击者的分析成本。有防御方案,自然就有攻击办法。如果Native方法是采用的静态注册,那可以通过grep命令在libs文件夹下进行筛选,如果Native方法采用的是动态注册,我们可以使用@lasting-yang大佬写的hook_RegisterNatives脚本,能够一步到位的定位到Native方法注册地址和所在的so文件,连分析JNI_OnLoad方法的过程也省了。如下所示,获取到x2方法所在的libxxx.so文件和函数偏移位置0x3f099
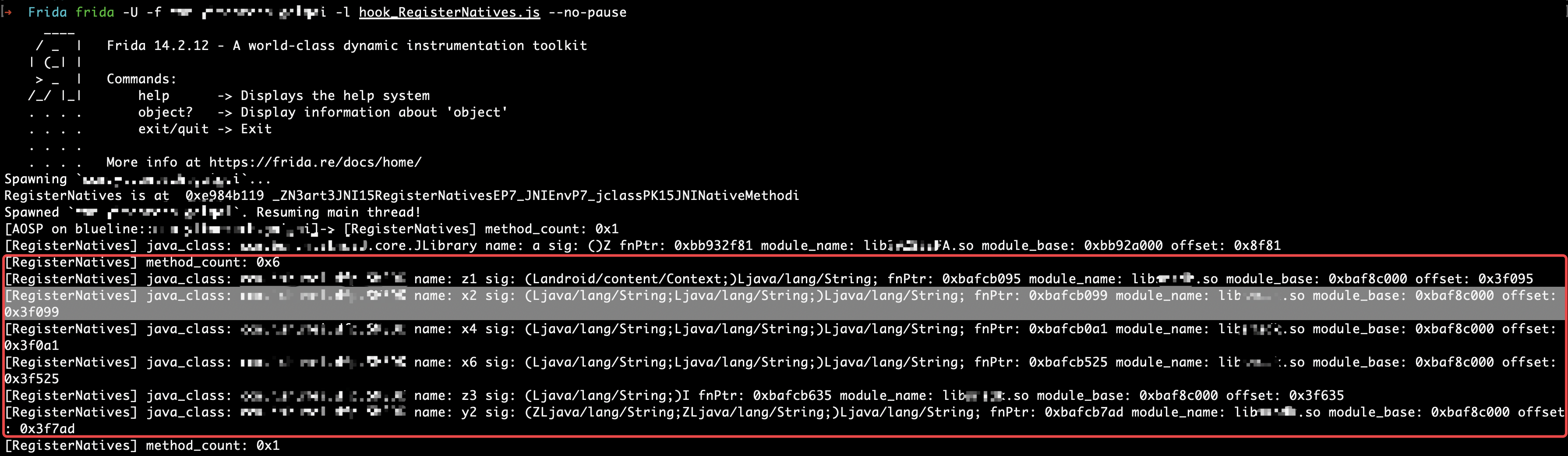
0x02 Native层分析
1. 硬刚O-LLVM
IDA打开libxxx.so文件,快捷键G跳转到0x3f099位置,伪代码如下所示

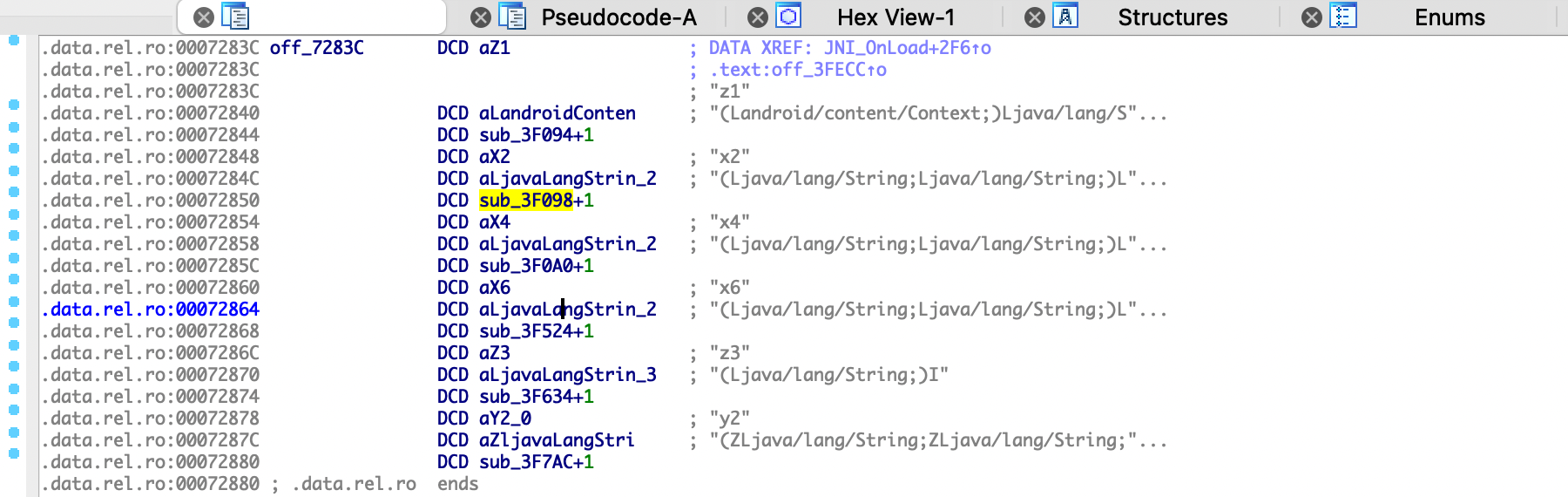
先快捷键X看看sub_3F098函数引用,在data.rel.ro段有被引用,如下所示,IDA自动解析出了JNINativeMethod结构体,确认x2方法的实现是sub_3F098函数(+1表示要转为Thumb模式)
继续看sub_3F098伪代码,直接调用了sub_3D17C,并传入a1,a3,a4变量。根据JNI函数定义可知,a1是JNIEnv结构体指针,a3对应Java层传入的arg1,a4对应arg2也就是指纹信息。跟进sub_3D17C函数,整个函数的控制流程图(CFG)如下
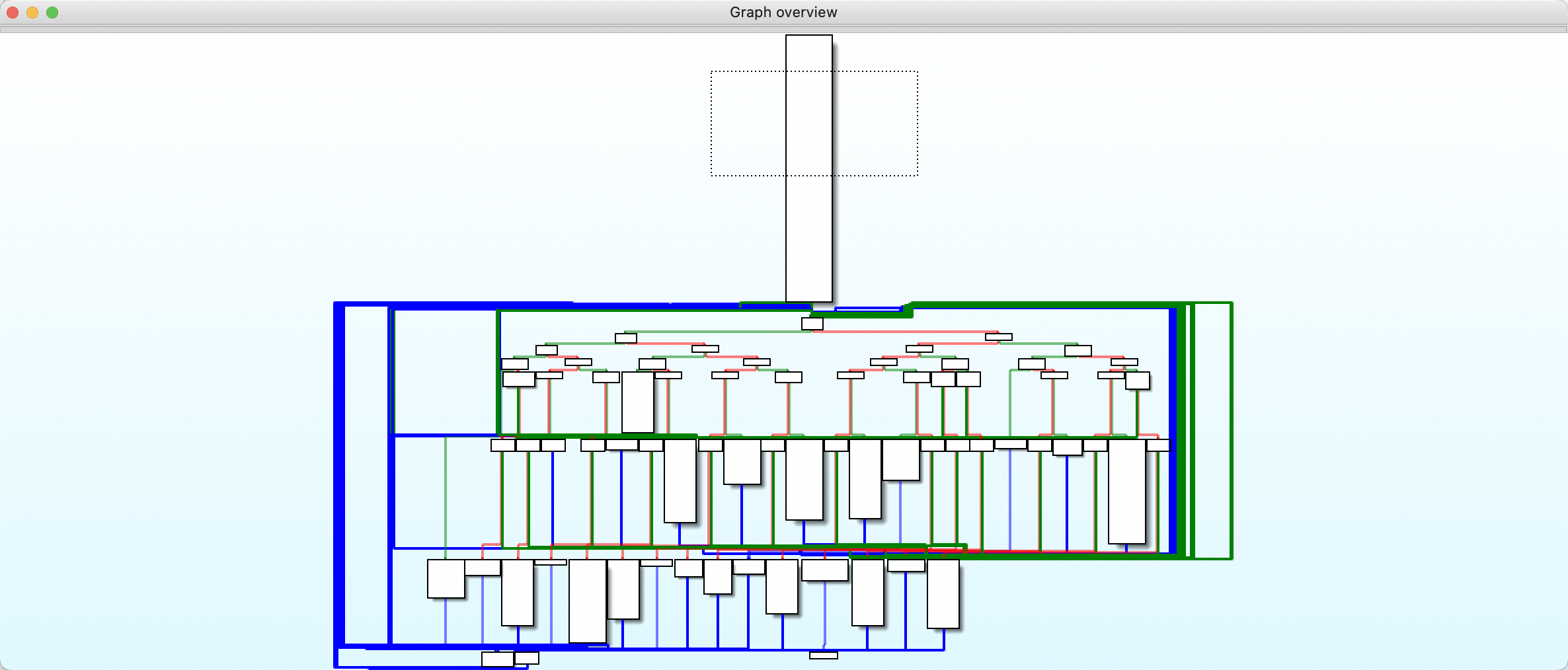
很明显代码使用ollvm-fla做了混淆处理,关于ollvm的的科普文章戳这里。把a1变量类型改成JNIEnv类型,简单优化后分析代码,发现函数里面只有一个return。这里就有两种分析思路了,第一种是根据return值逆向分析返回值的赋值过程,第二种则是根据传入的参数顺着程序逻辑分析,下面分别介绍下两种分析思路。
1.1 逆向分析
鼠标选中return的v61变量,快捷键X查看交叉引用,可以看见返回值由第310行的v44变量赋值
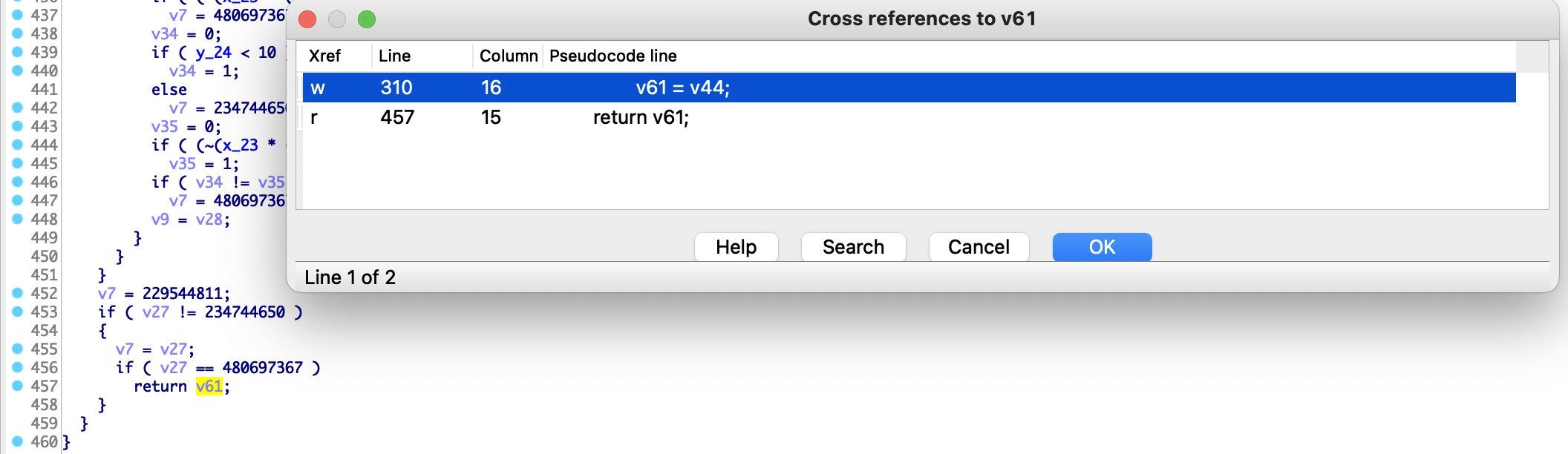
查看v44引用,如下所示,明显是通过v9赋值,NewStringUTF方法是出错后的返回值
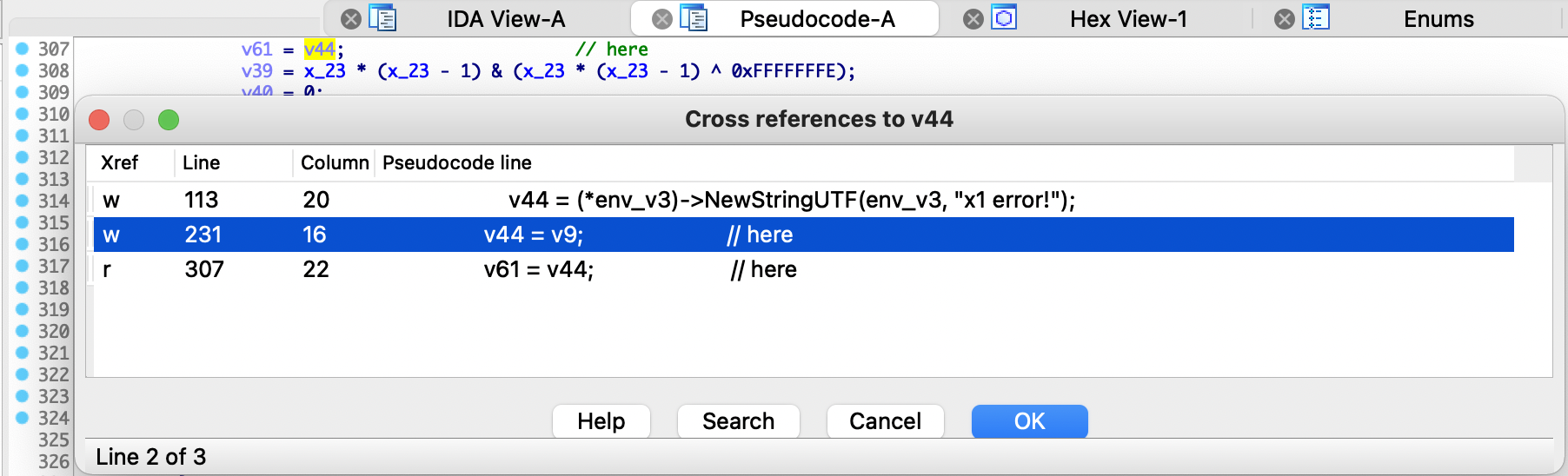
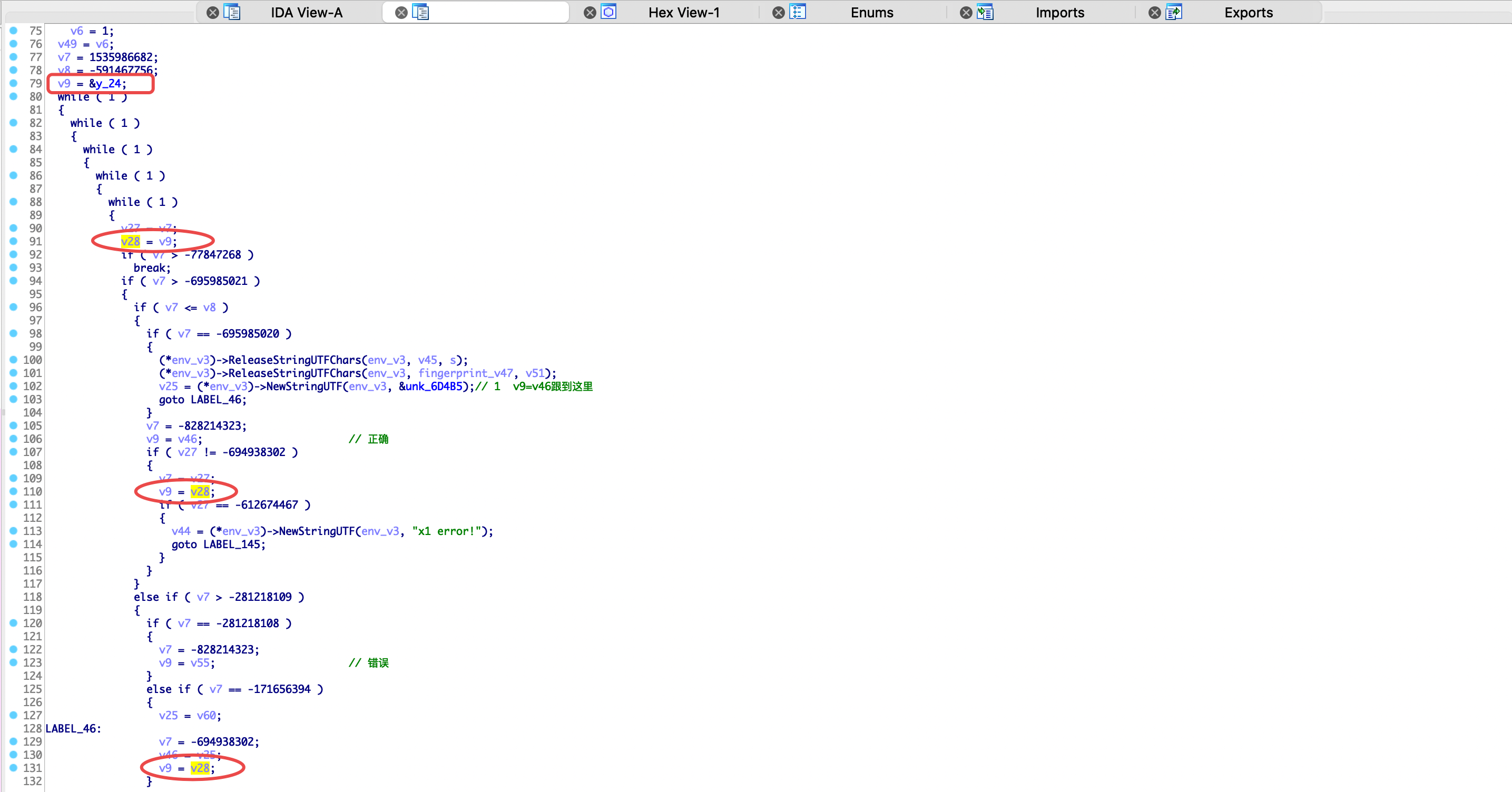
交叉引用v9参数,结果如下,这里的赋值节点看上去有点多,仔细分析一下发现其实就4处赋值。第一处是79行通过y_24赋值,查看一下伪代码是程序的初始化代码,直接排除。第二处是106行通过v46赋值,这个稍后详细分析。第三处是110行通过v28变量赋值,并且发现多处都在引用v28变量进行赋值,通过分析代码发现其实就是代码混淆后分发控制进行的循环赋值,以增加程序的流程。第四处是第123行通过v55赋值,通过分析代码发现该处赋值无效。
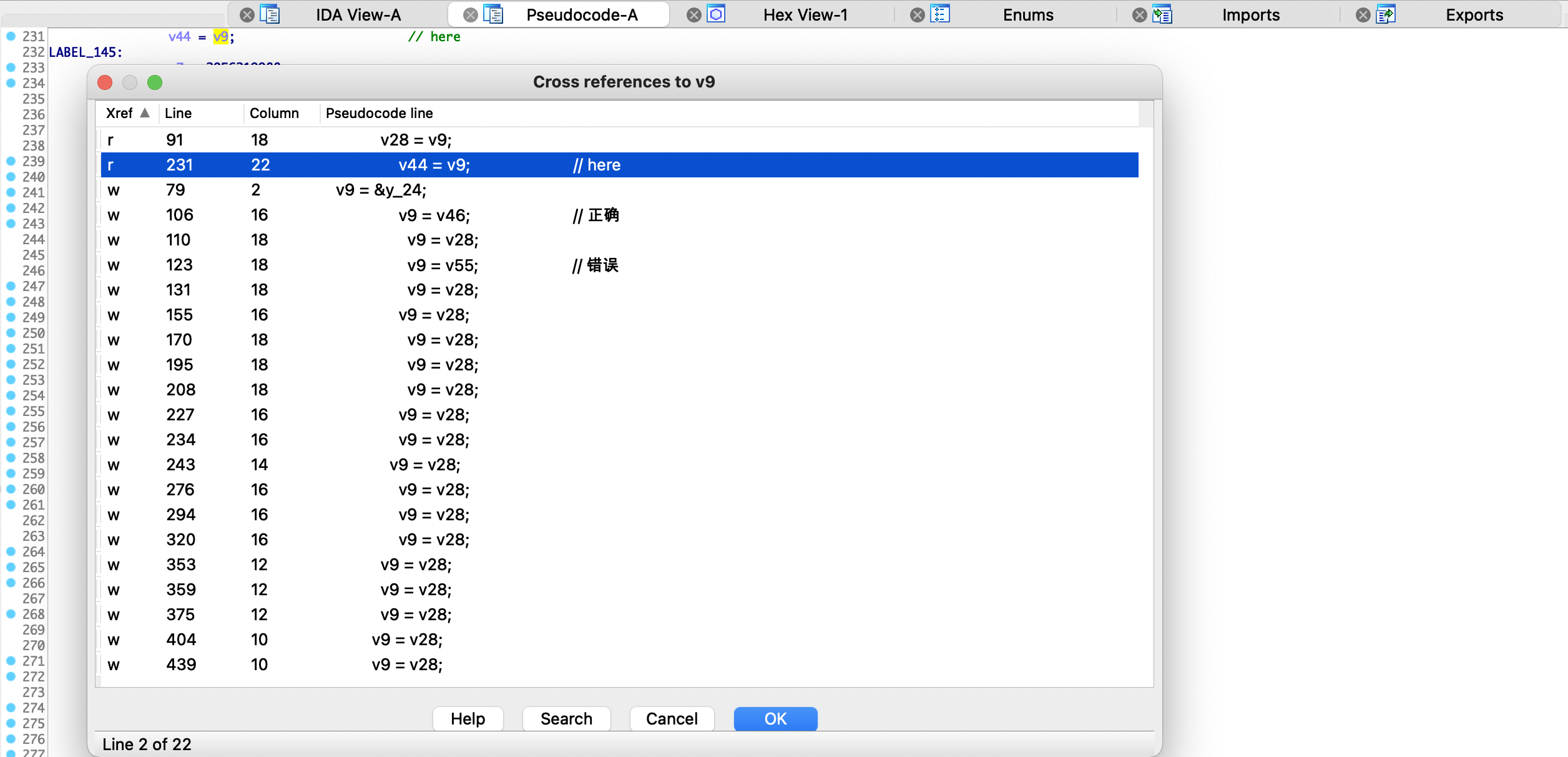
下面看代码分析,可以看见y_24是初始化赋值。再看v28的赋值逻辑,如下所示,分析可知是主分发器里变量的循环赋值,通过在if块里面改变v9的值执行不同的代码块,增加程序流程,达到混淆效果,分析CFG图会清晰点,这里就不贴图了。
继续看v55变量的代码分析,发现它是unk_6D4B5变量赋值的,该变量定义在rodata段,值等于0
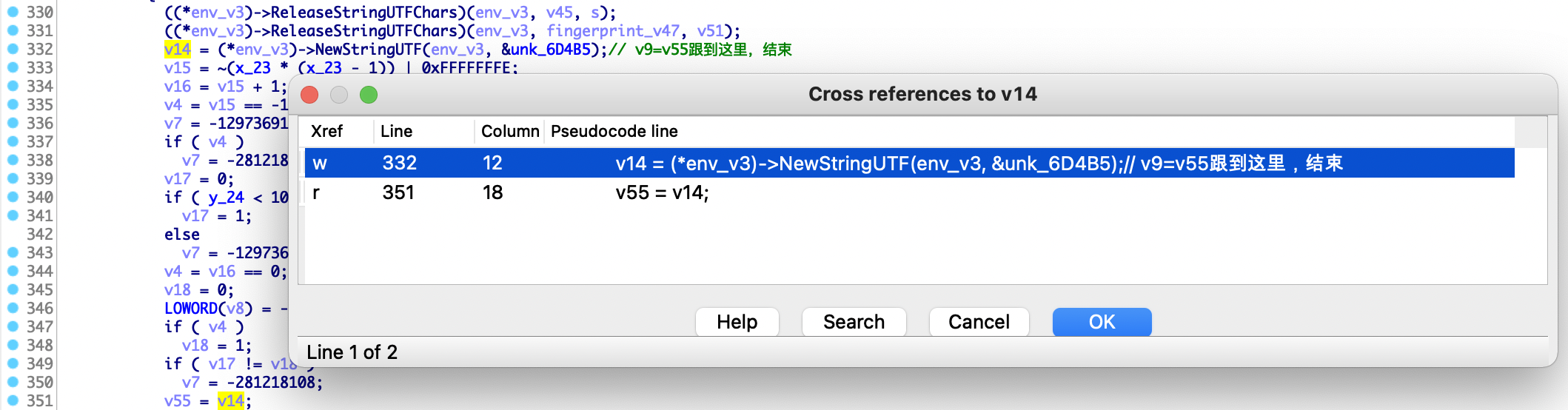
通过上述分析,发现除了v55变量不太清楚程序运行过程中有没有修改unk_6D4B5变量的值以外,其他y_24和v28都排除了。剩下的就是v46变量这条逻辑了,通过分析v46变量的赋值引用,发现其中也有通过unk_6D4B5变量赋值的地方,如下所示
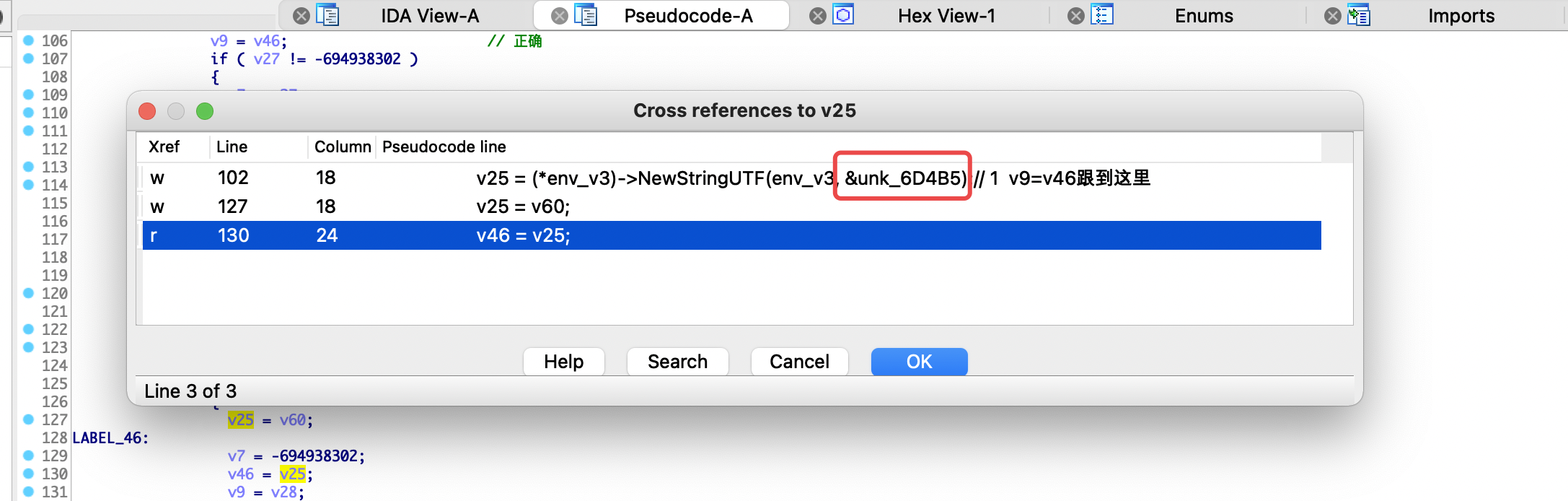
在分析过程中,发现v46有两处是通过unk_6D4B5变量赋值,剩下一处是通过v57变量赋值,如下所示,到此我们可以确定return的返回值是由unk_6D4B5变量或者v57变量赋值而来,但通过分析来看,v57这条线的可能性会大很多。具体可以通过动态调试确认一下,在调试之前先看看v57变量

v57先是传入了第163行的_aeabi_memclr函数,Google一下可知该函数的内部实现是调用的memset函数,把v57这个指针存储的数值初始化成0,并且根据函数原型可知,v62代表size_t长度。然后传入第164行的sub_3149C函数,这里除了ptr变量,其他3个变量的含义都是清楚的

进入sub_3149C函数,分析ptr和v57变量的赋值过程,发现变量都会传入sub_3140C函数,伪代码如下

aAbcdefghijklmn变量值如下,很明显这是base64编码的实现代码,可以参考c++的实现源码看看。

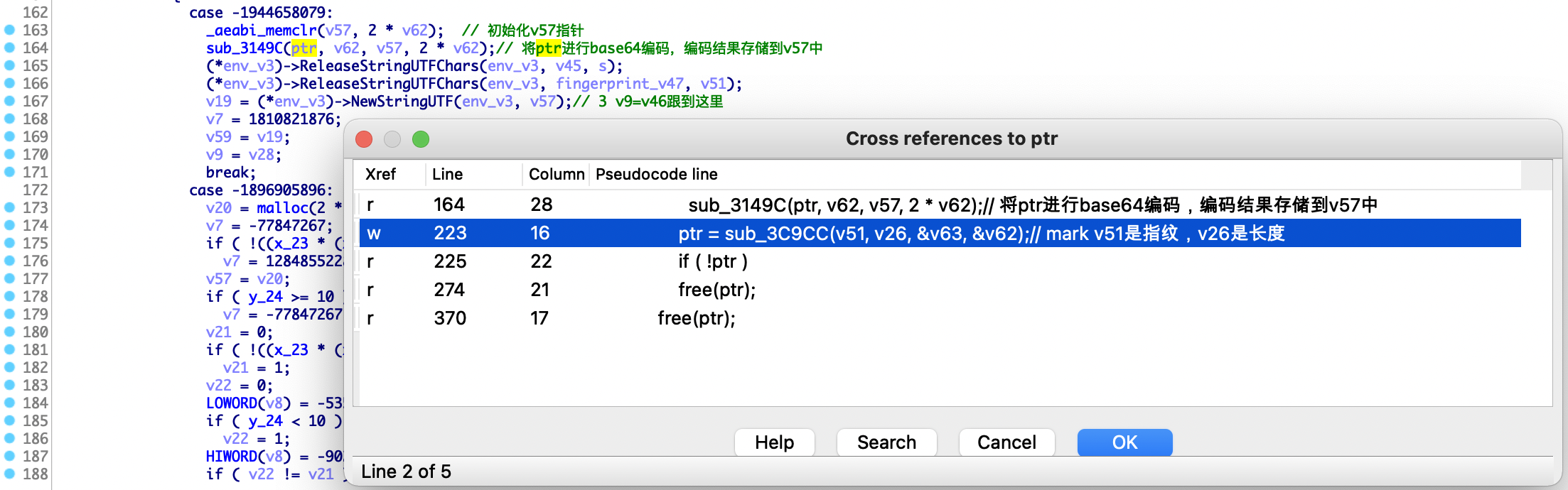
到这里明白了v57的赋值过程,先通过_aeabi_memclr函数初始化v57变量,然后将ptr传入sub_3149C函数进行base64编码,其结果存储到v57指针中。通过动态调试,确认为我们分析所述,也排除了unk_6D4B5变量赋值的分支逻辑。然后我们查看ptr的引用,定位到了sub_3C9CC函数
1.2 正向分析
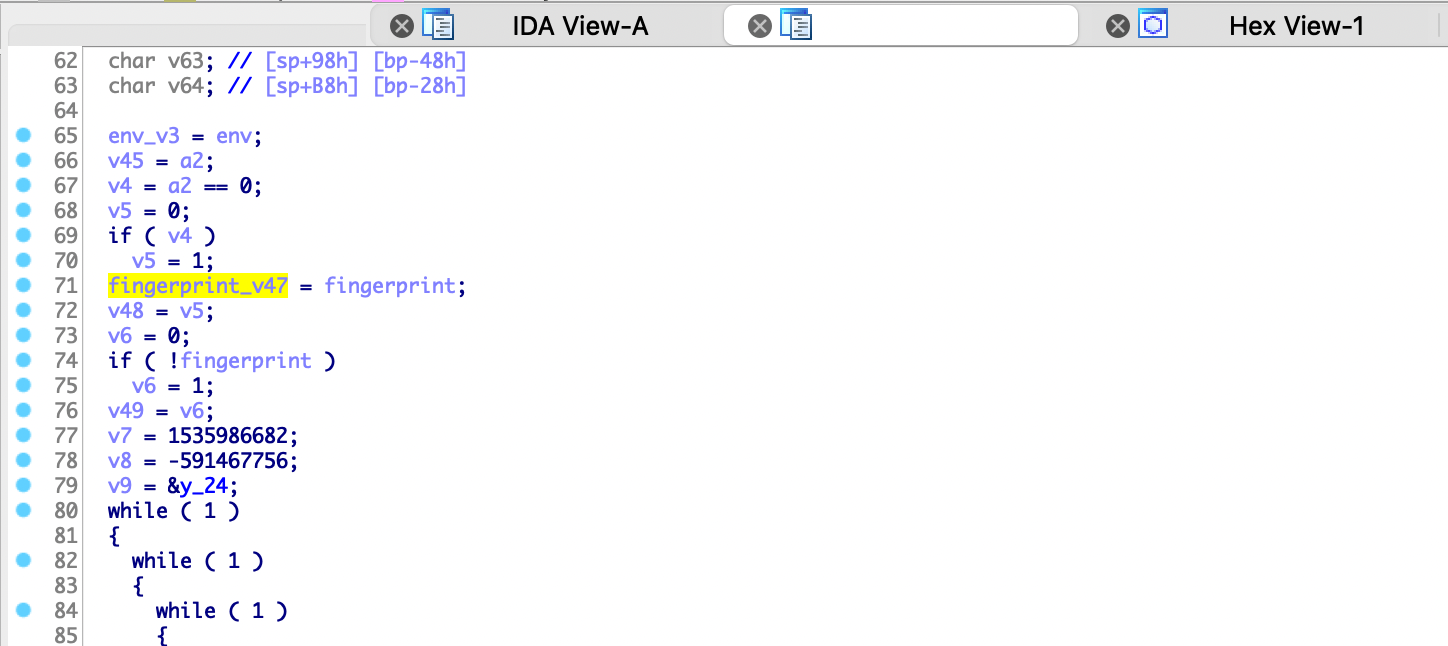
上面通过return的返回值逆向分析赋值逻辑,最终跟到了sub_3C9CC函数。接着我们直接分析传入sub_3D17C函数的参数变量,先快捷键N修改下变量名,查看代码发现传入的参数被直接重新赋值
查看fingerprint_v47引用,结果如下,可以看见就第199行获取chars,第221行在获取字符串length,其他都是release方法
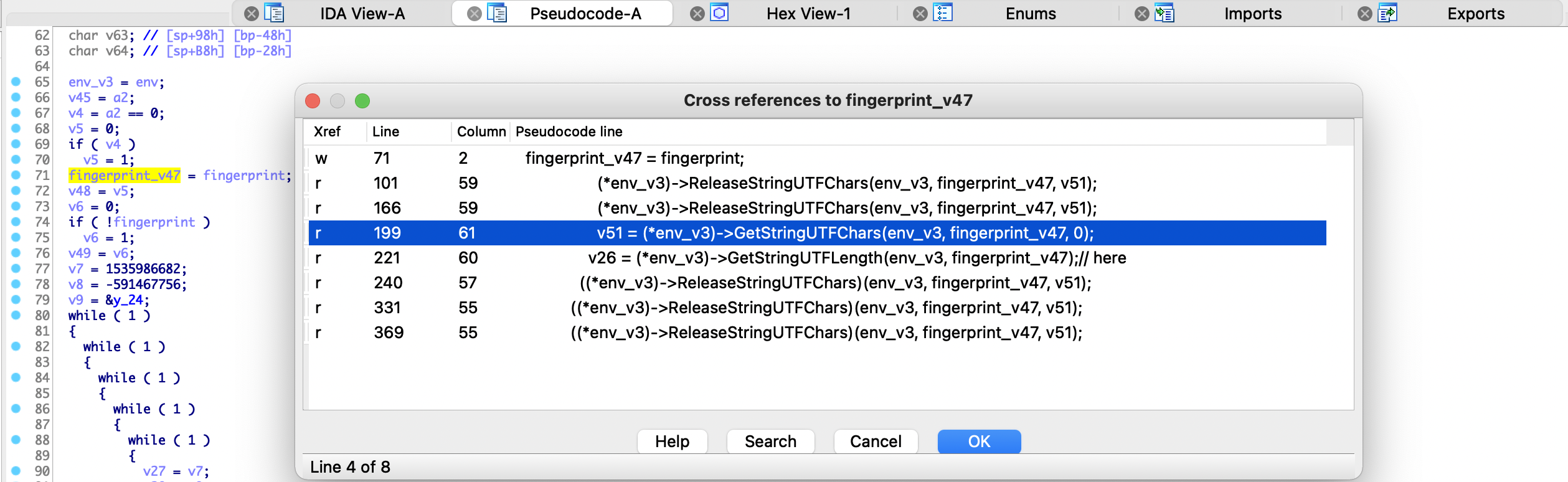
随便跟一个GetStringUTFXX方法,以第199行获取chars为例,查看v51变量引用,直接定位到了sub_3C9CC函数,同理v26变量也是传入了sub_3C9CC函数。通过传入的参数引用分析发现,这个函数的ollvm混淆结果实属鸡肋。
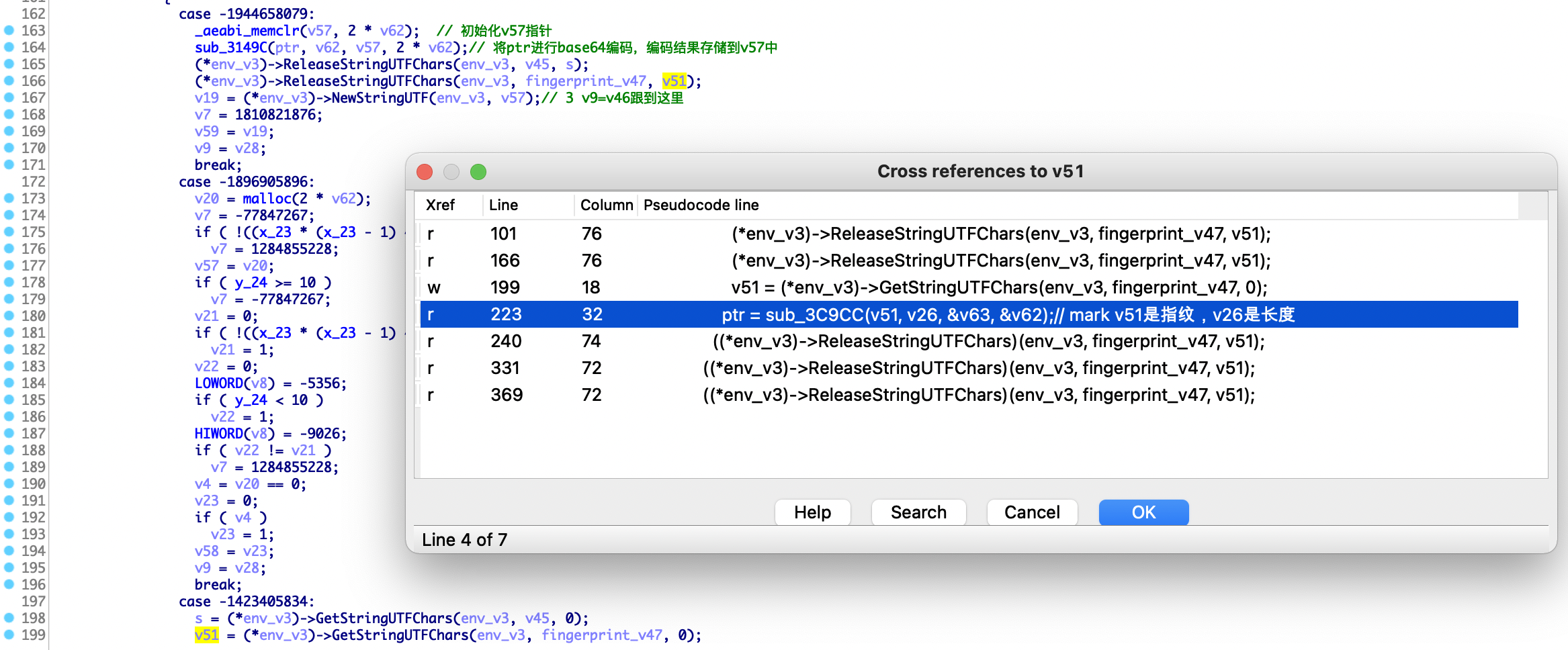
这里传入sub_3C9CC函数有四个参数,其中v51是Java层传入的指纹信息,v26是指纹的长度,剩下v63和v62意义不明确。分析发现,v63是sub_3549C函数返回的,Java层传入的arg1参数,正好也传入sub_3549C函数,分析该函数就是一个md5算法的实现,如下所示,sub_3549C函数中存在md5算法的4个固定常量,由此可以判断v63是表示arg1参数的md5值,剩下的v62变量含义不明。

2. 算法分析
跟进sub_3C9CC函数,函数的前三个变量分别是指纹信息、指纹的长度和MD5值,这里分析指纹信息或者MD5值,均能跟踪到以下代码位置

先看第212行sub_386B0函数,把Java层arg1参数的md5值传入了函数,分析变量引用,定位到以下代码位置

这里可以看见传入的md5值通过运算赋值给第452行的v44变量,接着v44赋值给第455行的v45变量,最后v45赋值给第458行的v57_ret变量,这里的v57_ret就是传入sub_386B0函数的第二个变量v70,相当于v70保存sub_386B0函数的返回值。
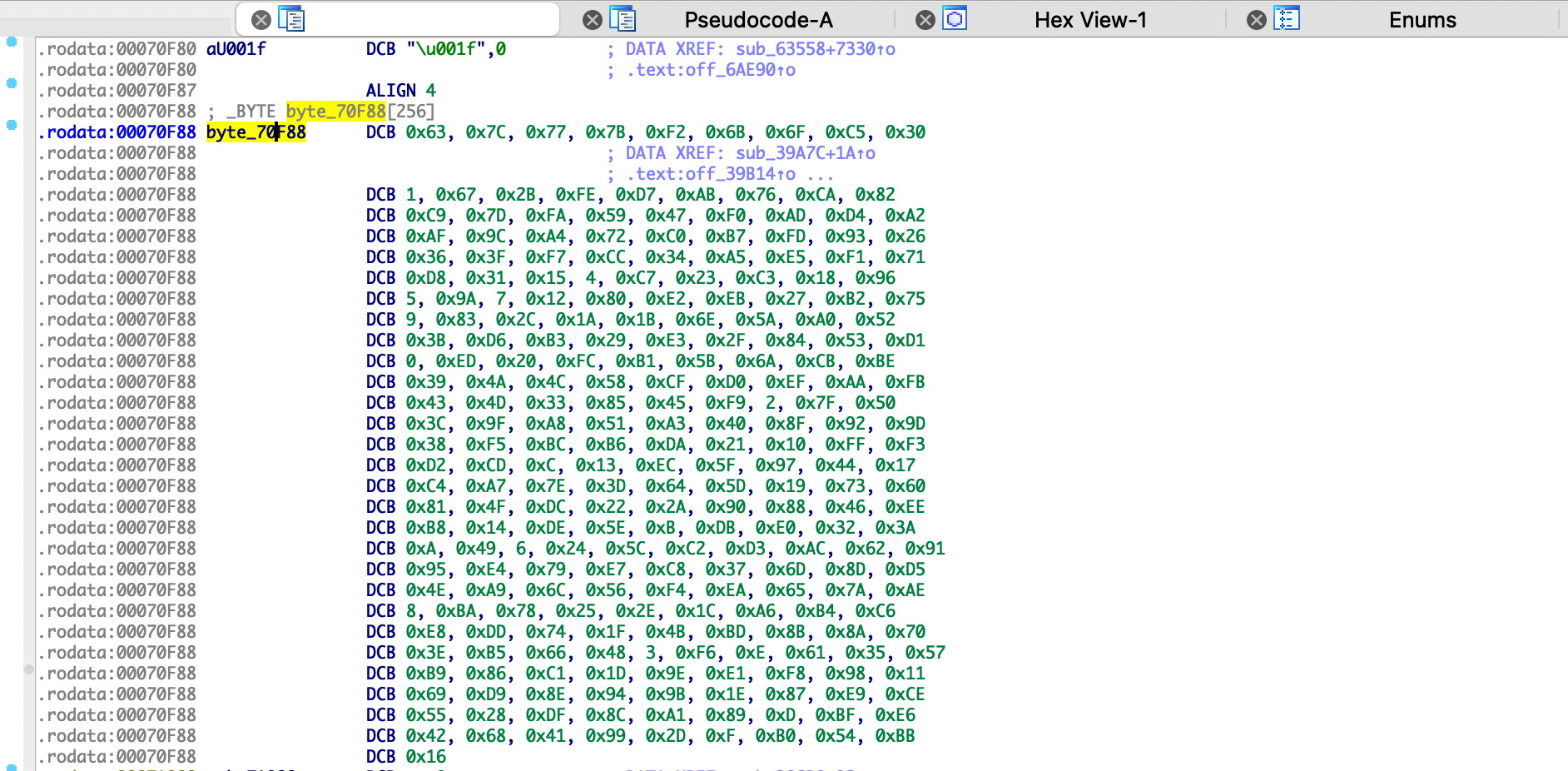
继续分析v57_ret变量引用,最终跟到sub_39A7C函数,该函数内有个byte_70F88数组,其值如下图所示,可知这是AES算法的S盒。由此我们可以判断加密指纹信息使用的是AES(Rijndael)算法,这里传入sub_386B0函数的只有一个md5值,可以推测该函数是AES算法的密钥扩展函数,明文密钥就是这个md5值,因为md5的长度是32字节等于256位,可以推测可能是AES256算法。
知道了加密指纹信息是使用的AES(Rijndael)算法,现在我们还需要找出下列关键信息:
加密模式
填充方式
数据块大小
密钥长度(256位)
加密密钥(md5值)
IV向量
根据sub_386B0密钥扩展函数的简单分析,我们暂时判断密钥为传入的md5值,密钥长度为256位。剩下的还需要分析加密模式,填充方式、IV向量以及数据块大小来判断是不是标准的AES算法。继续分析代码前先捋一捋标准AES算法的加密流程:
1. 将传入的明文字符串分成128bit(16字节)大小的若干字符串块;
1.1 如果最后一个字符串块不足128bit,则需要填充;
1.2 如果不填充(NoPadding),则要求传入的明文字符串长度必须是16字节的整数倍;
1.3 如果明文字符串长度正好是16的整数倍,但又设置了填充方式,则根据填充方式额外填充一个16字节的明文块;
1.4 如果有IV向量,第一个明文字符串块在初始轮前先和IV进行异或运算,相当于加盐。在加密第二个字符串块的时候,又将第一个字符串的加密结果作为IV向量与第二个字符串进行异或运算,后面依次循环;
2. 密钥扩展(每个明文块加密都要重新扩展),根据传入的密钥长度决定加密轮数,每轮密钥大小是128bit;
2.1 根据密钥大小128,192,256分别对应加密轮数是11,13,15轮(包含初始轮);
2.2 如果密钥大小是128,则初始轮所用的密钥就是原始密钥;
2.3 如果密钥大小是192,则初始轮(第0轮)是使用的原始密钥,第1轮的前64bit是原始密钥,剩下的则为扩展密钥,256同理;
3. 分割的128bit明文块分别依次进行加密,加密轮数由密钥大小决定,加密步骤为:
3.1 初始轮,加轮密钥;
3.2 第1轮到倒数第2轮的步骤都是一样的,每轮分别进行字节替换,行位移,列混淆,加轮密钥;
3.3 最后一轮不进行列混淆,只做字节替换,行位移,加轮密钥;
4. 将每个明文块的加密字符串拼接起来组成最后的加密字符串;
接下来我们就跟着这个加密流程分析,回到sub_3C9CC函数,继续分析第213行的sub_35DC4函数,传入了6个参数,其中第一个和第四个参数分别是指纹信息和密钥key,第五个参数等于常数256,第六个参数a6_01_30的值为”01020304050607084050607080102030”字符串,有点像IV向量,但是长度不对,通常AES算法的IV向量大小为16字节。
int __fastcall sub_35DC4(int a1_fingerprint, unsigned int a2, int a3, int a4_key, int a5_256, int a6_01_30)
跟进sub_35DC4函数,分析参数引用,定位到以下代码位置,第52行的memcpy函数显然是在将明文字符串分割成16字节大小的明文块,由此可知数据块为128位。a6_01_30变量通过第73行的memcpy拷贝了前16个字节数据,然后传入第53行的sub_35AE8函数,最后明文块和密钥key都传入了第54行的sub_3608C函数。

先看第53行的sub_35AE8函数,第一个参数是16byte大小的字符串,符合IV向量大小要求,第二个参数是128bit的明文块,分析传入函数的参数引用,定位到以下代码位置

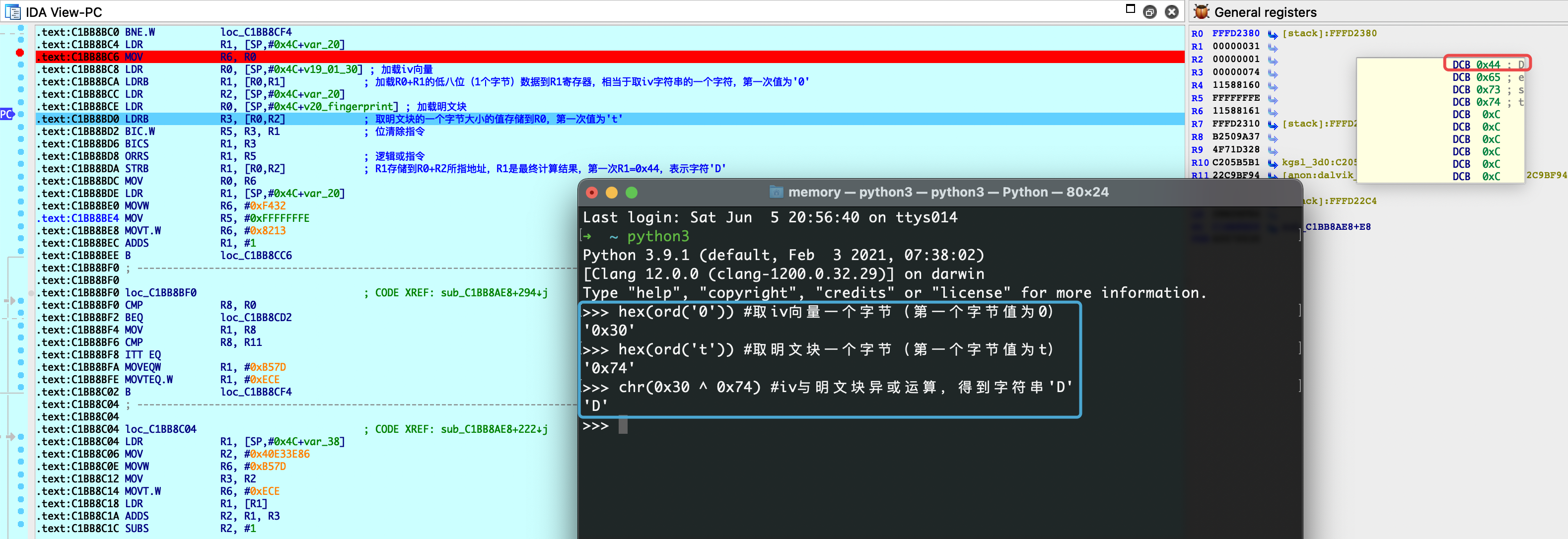
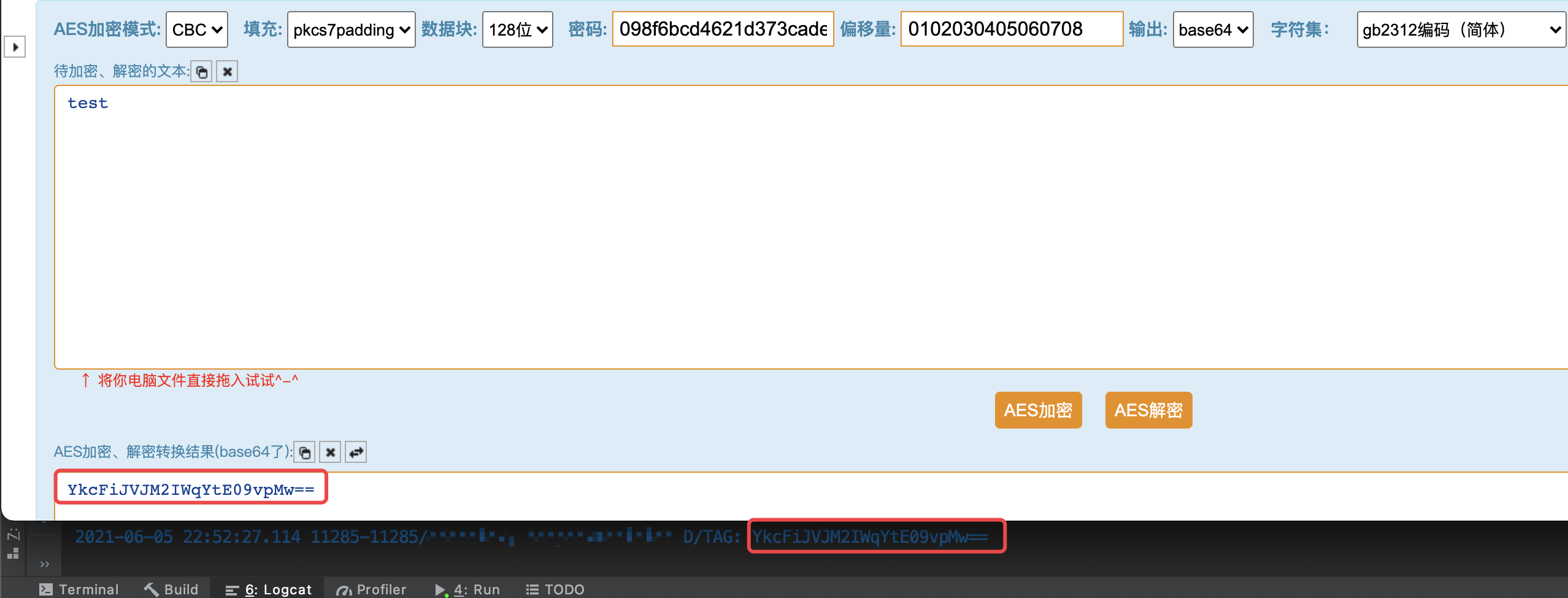
伪代码有点晦涩,动态调试下这段代码。因为原APP有反调试,我们自己写一个demo调用native方法,传入的指纹信息为”test”字符串。通过调试,结果如下,可知这段代码逻辑就是取iv向量与明文块逐字节进行异或运算,第一次iv为’0’,明文块第一字节为’t’,异或运算结果为’D’,第二次运算时,加载的明文块的第一个字节值已经从’t’变为了’D’。
到这里我们确定iv向量值为”0102030405060708”,那加密模式肯定不是ECB,应该是CBC模式了,并且通过R0寄存器的值可知”test”字符串是用0xC(十进制12)补齐的128bit(16字节)明文块,所以可以推测填充方式为PKCS7Padding。
接着看第54行的sub_3608C函数,这个函数的代码量不大,分析代码,跟进sub_39FE0函数,可以看见函数内部在使用byte_70F88数组(SBOX)进行字节替换,明显这就是AES256算法,进行了14轮加密。

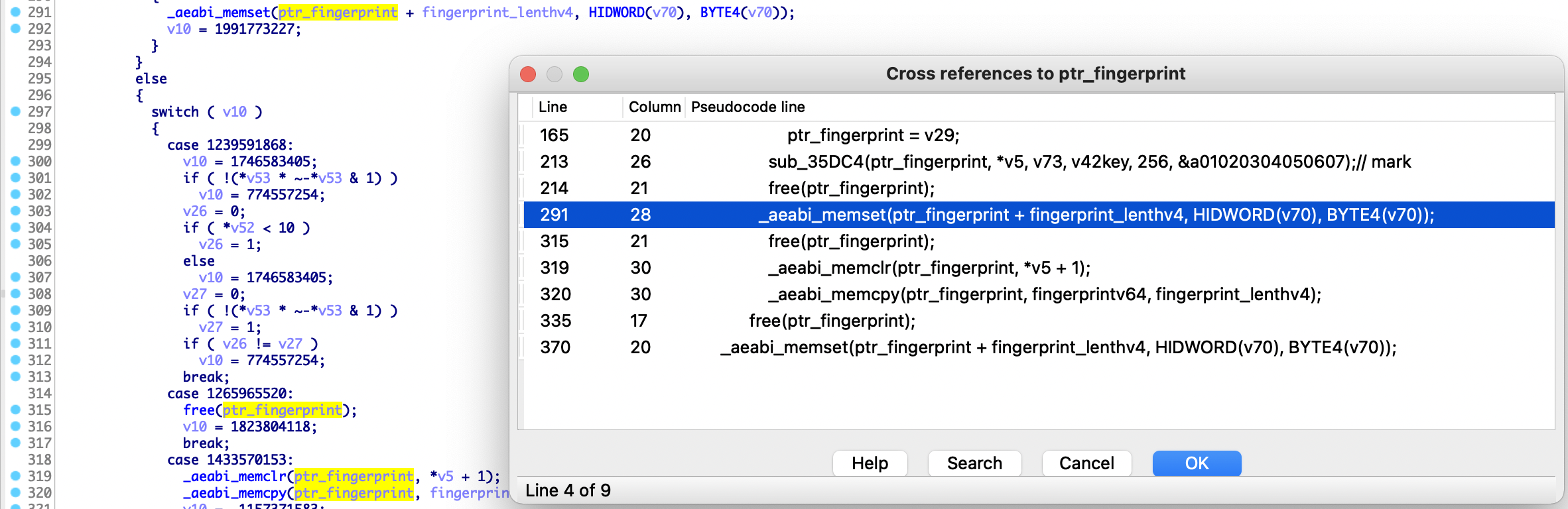
到此我们把AES的整体逻辑代码都分析出来了,但是填充方式还没静态分析出来,返回去再重头捋一捋。sub_35DC4函数里面的第52行直接使用memcpy对字符串进行128bit大小分块,接着传入sub_35AE8函数与IV进行异或运算,所以字符串填充在memcpy以前,往回分析指纹信息字符串,回到sub_3C9CC函数,通过分析发现下图的memset函数有重大嫌疑,具体需要调试分析下v70的值,笔者就不往下继续了。
到此,通过分析我们确认加密指纹信息所用的加密算法为AES/BCB/PKCS7Padding,IV值为’0102030405060708’,密钥为Java层传入的字符串的md5值。通过验证,确认加密结果和调用so加密的结果一致。
2.1 算法特征总结
最后,总结下AES算法的特征,以便往后遇到AES时可以快速定位确认。
- AES算法中存在一个固定的SBOX数组,元素个数为256个;
- 引用到SBOX的只有两处地方,密钥扩展和字节替换,有密钥参与的运算就是密钥扩展函数,字节替换后续跟着的是行位移,可以看见有行位移操作;
- AES算法中,传入的明文字符串会被分割成128bit大小的明文块,可以根据分割的数据块大小判断是否为标准AES算法;
- 明文块在初始轮加轮密钥操作前如果进行异或运算,证明存在IV向量;
- 如果有IV向量,证明一定不是ECB模式,如果没有IV向量,则可以判断为ECB模式;
- 可以根据明文块加密轮数判断密钥位数,密钥大小128,192,256分别对应加密轮数是11,13,15轮(包含初始轮);
- 待加密的明文字符串长度一定是16字节的整数倍,否则就需要填充,如果填充0x0,则为ZeroPadding,如果填充值为一个明文块缺少的字节数,则为PKCS7Padding。注: AES算法标准中没有PKCS5Padding填充,该填充方式为历史遗留产物,内部实现其实也是PKCS7Padding。
- 分析算法时可以控制明文字符串的长度(使它不足16byte),通过调试可以快速确认填充方式;
- AES128算法中,密钥扩展的第一个密钥就是明文密钥(128bit),AES256中,密钥扩展的前两个密钥为明文密钥(128+128=256bit);
- 查找SBOX可以使用插件findcrypt-yara;
0x03 结语
结合前两篇Native层分析的文章,基本把Native层逆向破解的知识点都覆盖到了,作为入门学习应该是差不多了。本来还想通过这个so文件再聊一聊ollvm的反混淆,但是一起写到这篇文章里面可能显得内容太过于混杂,想了想还是下次单独写篇文章吧。笔者水平有限,文章中如有理解错误的地方,还请不吝赐教。
版权声明:转载请注明出处,谢谢。https://github.com/curz0n